

Introducing InQuanto v4.0
The latest version of our advanced quantum computational chemistry platform
║┌┴Ž╔ń is excited to announce the release of InQuantoŌäó v4.0, the latest version of our advanced quantum computational chemistry software. This update introduces new features and significant performance improvements, designed to help both industry and academic researchers accelerate their computational chemistry work.
If you're new to InQuanto or want to learn more about how to use it, we encourage you to explore our documentation.
InQuanto v4.0 is being released alongside ║┌┴Ž╔ń Nexus, our cloud-based platform for quantum software. Users with Nexus access can leverage the `inquanto-nexus` extension to, for example, take advantage of multiple available backends and seamless cloud storage.
In addition, InQuanto v4.0 introduces enhancements that allow users to run larger chemical simulations on quantum computers. Systems can be easily imported from classical codes using the widely supported FCIDUMP file format. These fermionic representations are then efficiently mapped to qubit representations, benefiting from performance improvements in InQuanto operators. For systems too large for quantum hardware experiments, users can now utilize the new `inquanto-cutensornet` extension to run simulations via tensor networks.
These updates enable users to compile and execute larger quantum circuits with greater ease, while accessing powerful compute resources through Nexus.
║┌┴Ž╔ń Nexus┬Ā
InQuanto v4.0 is fully integrated with via the `inquanto-nexus` extension. This integration allows users to easily run experiments across a range of quantum backends, from simulators to hardware, and access results stored in Nexus cloud storage.
Results can be annotated for better searchability and seamlessly shared with others. Nexus also offers the Nexus Lab, which provides a preconfigured Jupyter environment for compiling circuits and executing jobs. The Lab is set up with InQuanto v4.0 and a full suite of related software, enabling users to get started quickly.┬Ā
Enhanced Operator Performance
The `inquanto.mappings` submodule has received a significant performance enhancement in InQuanto v4.0. By integrating a set of operator classes written in C++, the team has increased the performance of the module past that of other open-source packagesŌĆÖ equivalent methods.┬Ā
Like any other Python package, InQuanto can benefit from delegating tasks with high computational overhead to compiled languages such as C++. This prescription has been applied to the qubit encoding functions of the `inquanto.mappings` submodule, in which fermionic operators are mapped to their qubit operator equivalents. One such qubit encoding scheme is the Jordan-Wigner (JW) transformation.┬ĀWith respect to JW encoding as a benchmarking task, the integration of C++ operator classes in InQuanto v4.0 has yielded an execution time speed-up of two and a half times that of open-source competitors (Figure 1).
ŌĆŹ

Figure 1. Performance comparison of Jordan Wigner (JW) operator mappings for LiH molecule in several basis sets of increasing size.┬Ā
This is a substantial increase in performance that all users will benefit from. InQuanto users will still interact with the familiar Python classes such as `FermionOperator` and `QubitOperator` in v4.0. However, when the `mappings` module is called, the Python operator objects are converted to C++ equivalents and vice versa before and after the qubit encoding procedure (Figure 2). With future total integration of C++ operator classes, we can remove the conversion step and push the performance of the `mappings` module further. Tests, once again using the JW mappings scheme, show a 40 times execution time speed-up as compared to open-source competitors (Figure 1).
ŌĆŹ

Figure 2. Representation of the conversion step from Python objects to C++ objects in the qubit encoding processes handled by the `inquanto.mappings` submodule in InQuanto v4.0.
Efficient classical pre-processing implementations such as this are a crucial step on the path to quantum advantage.┬ĀAs the number of physical qubits available on quantum computers increases, so will the size and complexity of the physical systems that can be simulated. To support this hardware upscaling, computational bottlenecks including those associated with the classical manipulation of operator objects must be alleviated. Aside from keeping pace with hardware advancements, it is important to enlarge the tractable system size in situations that do not involve quantum circuit execution, such as tensor network circuit simulation and resource estimation.
Leveraging Tensor Networks
Users with access to GPU capabilities can now take advantage of tensor networks to accelerate simulations in InQuanto v4.0. This is made possible by the `inquanto-cutensornet` extension, which interfaces InQuanto with the NVIDIA® cuTensorNet library. The `inquanto-cutensornet` extension leverages the `pytket-cutensornet` , which facilitates the conversion of `pytket` circuits into tensor networks to be evaluated using the NVIDIA® cuTensorNet library. This extension increases the size limit of circuits that can be simulated for chemistry applications. Future work will seek to integrate this functionality with our Nexus platform, allowing InQuanto users to employ the extension without requiring access to their own local GPU resources.
Here we demonstrate the use of the `CuTensorNetProtocol` passed to a VQE experiment. For the sake of brevity, we use the `get_system` method of `inquanto.express` to swiftly define the system, in this case H2 using the STO-3G basis-set.
from inquanto.algorithms import AlgorithmVQE
from inquanto.ansatzes import FermionSpaceAnsatzUCCD
from inquanto.computables import ExpectationValue, ExpectationValueDerivative
from inquanto.express import get_system
from inquanto.mappings import QubitMappingJordanWigner
from inquanto.minimizers import MinimizerScipy
from inquanto.extensions.cutensornet import CuTensorNetProtocol
fermion_hamiltonian, space, state = get_system("h2_sto3g.h5")
qubit_hamiltonian = fermion_hamiltonian.qubit_encode()
ansatz = FermionSpaceAnsatzUCCD(space, state, QubitMappingJordanWigner())
expectation_value = ExpectationValue(ansatz, qubit_hamiltonian)
gradient_expression = ExpectationValueDerivative(
ansatz, qubit_hamiltonian, ansatz.free_symbols_ordered()
)
protocol_tn = CuTensorNetProtocol()
vqe_tn = (
AlgorithmVQE(
objective_expression=expectation_value,
gradient_expression=gradient_expression,
minimizer=MinimizerScipy(),
initial_parameters=ansatz.state_symbols.construct_zeros(),
)
.build(protocol_objective=protocol_tn, protocol_gradient=protocol_tn)
.run()
)
print(vqe_tn.generate_report()["final_value"])
# -1.136846575472054
The inherently modular design of InQuanto allows for the seamless integration of new extensions and functionality. For instance, a user can simply modify existing code using `SparseStatevectorProtocol` to enable GPU acceleration through `inquanto-cutensornet`. It is worth noting that the extension is also compatible with shot-based simulation via the `CuTensorNetShotsBackend` provided by `pytket-cutensornet`.
ŌĆ£Hybrid quantum-classical supercomputing is accelerating quantum computational chemistry research,ŌĆØ said Tim Costa, Senior Director at NVIDIA┬«. ŌĆ£With ║┌┴Ž╔ńŌĆÖs InQuanto v4.0 platform and NVIDIAŌĆÖs cuQuantum SDK, InQuanto users now have access to unique tensor-network-based methods, enabling large-scale and high-precision quantum chemistry simulations.ŌĆØ
Classical Code Interface
As demonstrated by our `inquanto-pyscf` , we want InQuanto to easily interface with classical codes. In InQuanto v4.0, we have clarified integration with other classical codes such as Gaussian and Psi4. All that is required is an FCIDUMP file, which is a common output file for classical codes. An FCIDUMP file encodes all the one and two electron integrals required to set up a CI Hamiltonian. Users can bring their system from classical codes by passing an FCIDUMP file to the `FCIDumpRestricted` class and calling the `to_ChemistryRestrictedIntegralOperator` method or its unrestricted counterpart, depending on how they wish to treat spin. The resulting InQuanto operator object can be used within their workflow as they usually would.
Exposing TKET Compilation
Users can experiment with TKETŌĆÖs latest circuit compilation tools in a straightforward manner with InQuanto v4.0. Circuit compilation now only occurs within the `inquanto.protocols` module. This allows users to define which optimization passes to run before and/or after the backend specific defaults, all in one line of code. Circuit compilation is a crucial step in all InQuanto workflows. As such, this structural change allows us to cleanly integrate new functionality through extensions such as `inquanto-nexus` and `inquanto-cutensornet`. Looking forward, beyond InQuanto v4.0, this change is a positive step towards bringing quantum error correction to InQuanto.
Conclusion
InQuanto v4.0 pushes the size of the chemical systems that a user can simulate on quantum computers. Users can import larger, carefully constructed systems from classical codes and encode them to optimized quantum circuits. They can then evaluate these circuits on quantum backends with `inquanto-nexus` or execute them as tensor networks using `inquanto-cutensornet`. We look forward to seeing how our users leverage InQuanto v4.0 to demonstrate the increasing power of quantum computational chemistry. If you are curious about InQuanto and want to read further, our initial release is very informative or visit the InQuanto website.
How to Access InQuanto
If you are interested in trying InQuanto, please request access or a demo at inquanto@quantinuum.com
About ║┌┴Ž╔ń
║┌┴Ž╔ń,┬Āthe worldŌĆÖs largest integrated quantum company, pioneers powerful quantum computers and advanced software solutions. ║┌┴Ž╔ńŌĆÖs technology drives breakthroughs in materials discovery, cybersecurity, and next-gen quantum AI. With over 500 employees, including 370+ scientists and engineers, ║┌┴Ž╔ń leads the quantum computing revolution across continents.┬Ā
┤Ī│▄│┘│¾┤Ū░∙▓§:╠²
║┌┴Ž╔ń (alphabetical order): Eric Brunner, Steve Clark, Fabian Finger, Gabriel Greene-Diniz, Pranav Kalidindi, Alexander Koziell-Pipe, David Zsolt Manrique, Konstantinos Meichanetzidis, Frederic Rapp
Hiverge (alphabetical order): Alhussein Fawzi, Hamza Fawzi, Kerry He, Bernardino Romera Paredes, Kante Yin
ŌĆŹ
What if every quantum computing researcher had an army of students to help them write efficient quantum algorithms? Large Language Models are starting to serve as such a resource.
║┌┴Ž╔ńŌĆÖs processors offer world-leading fidelity, and recent experiments show that they have surpassed the limits of classical simulation for certain computational tasks, such as simulating materials. However, access to quantum processors is limited and can be costly. It is therefore of paramount importance to optimise quantum resources and write efficient quantum software. Designing efficient algorithms is a challenging task, especially for quantum algorithms: dealing with superpositions, entanglement, and interference can be counterintuitive.
To this end, our joint team used AI platform for automated algorithm discovery, the Hive, to probe the limits of what can be done in quantum chemistry. The Hive generates optimised algorithms tailored to a given problem, expressed in a familiar programming language, like Python. Thus, the HiveŌĆÖs outputs allow for increased interpretability, enabling domain experts to potentially learn novel techniques from the AI-discovered solutions. Such AI-assisted workflows lower the barrier of entry for non-domain experts, as an initial sketch of an algorithmic idea suffices to achieve state-of-the-art solutions.
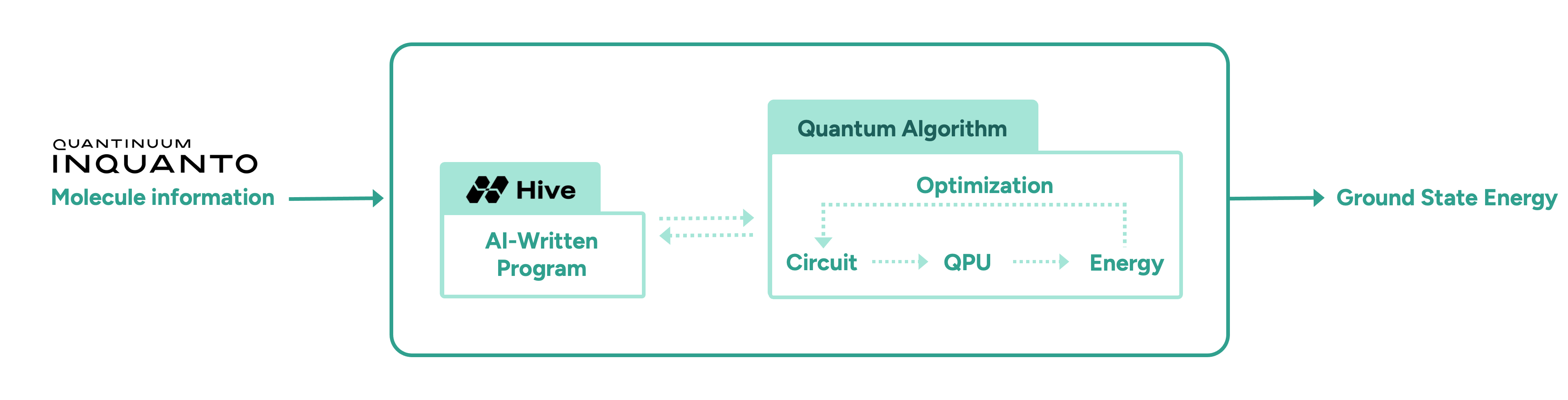
In this initial proof-of-concept study, we demonstrate the advantage of AI-driven algorithmic discovery of efficient quantum heuristics in the context of quantum chemistry, in particular the electronic structure problem. Our early explorations show that the Hive can start from a naïve and simple problem statement and evolve a highly optimised quantum algorithm that solves the problem, reaching chemical precision for a collection of molecules. Our high-level workflow is shown in Figure 1. Specifically, the quantum algorithm generated by the Hive achieves a reduction in the quantum resources required by orders of magnitude compared to current state-of-the-art quantum algorithms. This promising result may enable the implementation of quantum algorithms on near-term hardware that was previously thought impossible due to current resource constraints.
The Electronic Structure Problem in Quantum Chemistry
The electronic structure problem is central to quantum chemistry. The goal is to prepare the ground state (the lowest energy state) of a molecule and compute the corresponding energy of that state to chemical precision or beyond. Classically, this is an exponentially hard problem. In particular, classical treatments tend to fall short when there are strong quantum effects in the molecule, and this is where quantum computers may be advantageous.
The paradigm of variational quantum algorithms is motivated by near-term quantum hardware. One starts with a relatively easy-to-prepare initial state. Then, the main part of the algorithm consists of a sequence of parameterised operators representing chemically meaningful actions, such as manipulating electron occupations in the molecular orbitals. These are implemented in terms of parameterised quantum gates. Finally, the energy of the state is measured via the moleculeŌĆÖs energy operator, the ŌĆ£HamiltonianŌĆØ, by executing the circuit on a quantum computer and measuring all the qubits on which the circuit is implemented. Taking many measurements, or ŌĆ£shotsŌĆØ, the energy is estimated to the desired precision. The ground state energy is found by iteratively optimising the parameters of the quantum circuit until the energy converges to a minimum value. The general form of such a variational quantum algorithm is illustrated in Figure 2.
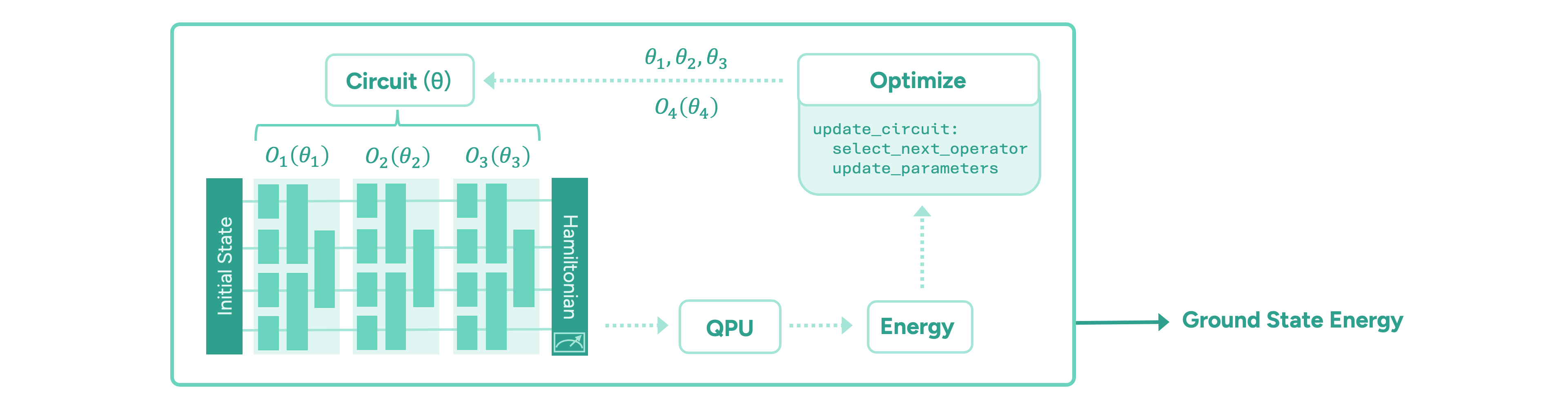
The main challenge in these frameworks is to design an appropriate quantum circuit architecture, i.e. find an efficient sequence of operators, and an efficient optimisation strategy for its parameters. It is important to minimise the number of quantum operations in any given circuit, as each operation is inherently noisy and the algorithmŌĆÖs output degrades exponentially. Another important quantum resource to be minimised is the total number of circuits that need to be evaluated to compute the energy values during the optimisation of the circuit parameters, which is time-consuming.
To meet these challenges, we task the Hive with designing a variational quantum algorithm to solve the ground state problem, following the workflow shown in Figure 1. The Hive is a distributed evolutionary process that evolves programs. It uses Large Language Models to generate mutations in the form of edits to an entire codebase. This genetic process selects the fittest programs according to how well they solve a given problem. In our case, the role of the quantum computer is to compute the fitness, i.e., the ground state energy. Importantly, the Hive operates at the level of a programming language; it readily imports and uses all known libraries that a human researcher would use, including ║┌┴Ž╔ńŌĆÖs quantum chemistry platform, InQuanto. In addition, the Hive can accept instructions and requests in natural language, increasing its flexibility. For example, we encouraged it to seek parameter optimisation strategies that avoid estimating gradients, as this incurs significant overhead in terms of circuit evaluations. ┬ĀIntuitively, the interaction between a human scientist and the Hive is analogous to a supervisor and a group of eager and capable students: the supervisor provides guidance at a high level, and the students collaborate and flesh out the general idea to produce a working solution that the supervisor can then inspect.
We find that from an extremely basic starting point, consisting of a skeleton for a variational quantum algorithm, the Hive can autonomously assemble a bespoke variational quantum algorithm, which we call Hive-ADAPT. Specifically, the Hive evolves heuristic functions that construct a circuit as a sequence of quantum operators and optimise its parameters. Remarkably, the Hive converged on a structure resembling the current state-of-the-art, ADAPT-VQE. Crucially, however, Hive-ADAPT substantially outperforms this baseline, delivering significant improvements in chemical precision while reducing quantum resource requirements.
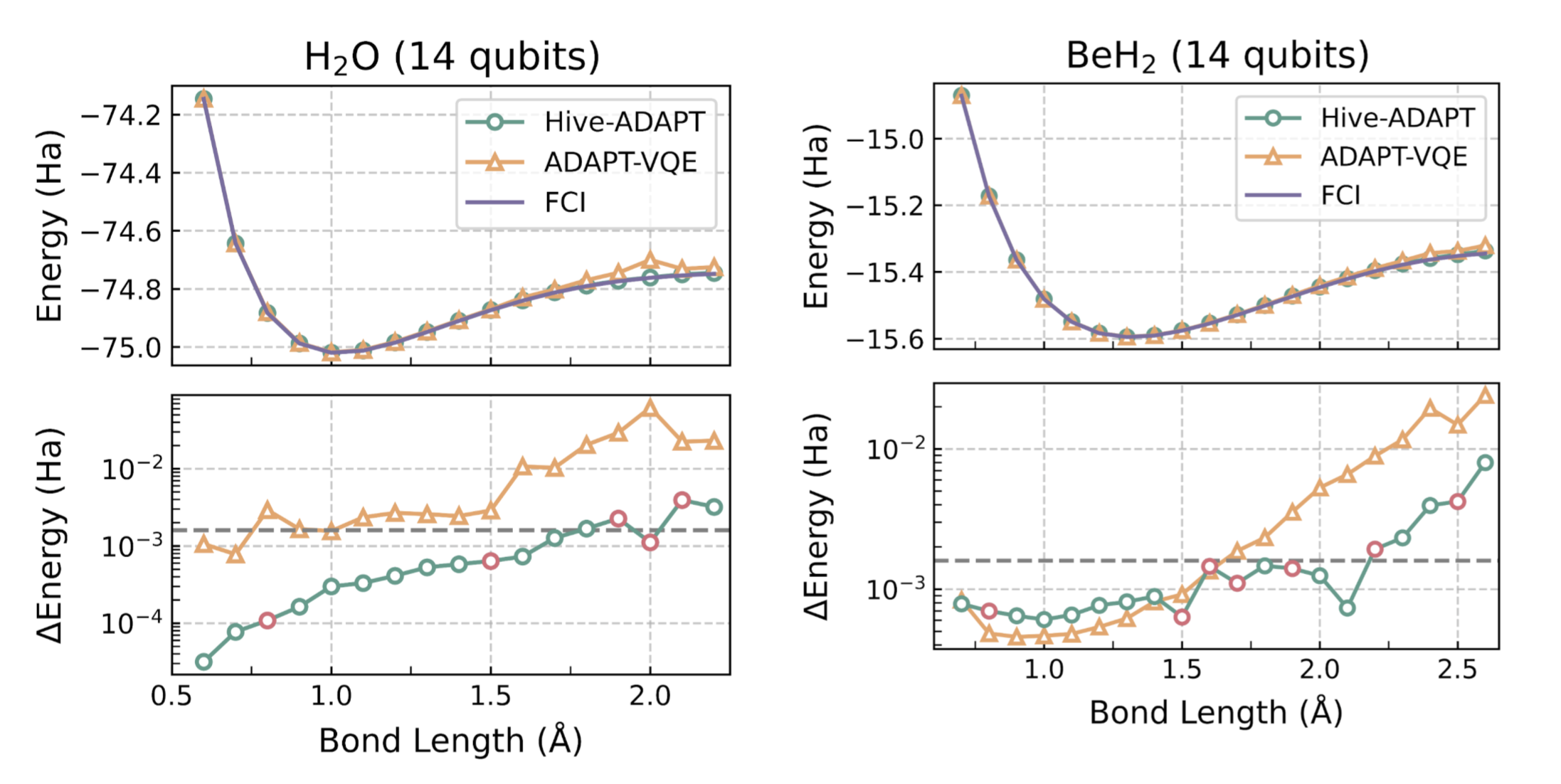
A moleculeŌĆÖs ground state energy varies with the distances between its atoms, called the ŌĆ£bond lengthŌĆØ. For example, for the molecule H2O, the bond length refers to the length of the O-H bond. The Hive was tasked with developing an algorithm for a small set of bond lengths and reaching chemical precision, defined as within 1.6e-3 Hartree (Ha) of the ground state energy computed with the exact Full Configuration Interaction (FCI) algorithm. As we show in Figure 3, remarkably, Hive-ADAPT achieves chemical precision for more bond lengths than ADAPT-VQE. Furthermore, Hive-ADAPT also reaches chemical precision for other ŌĆ£unseenŌĆØ bond lengths, showcasing the generalisation ability of the evolved quantum algorithm. Our results were obtained from classical simulations of the quantum algorithms, where we used NVIDIA CUDA-Q to leverage the parallelism enabled by GPUs. Further, relative to ADAPT-VQE, Hive-ADAPT exhibits one to two orders of magnitude reduction in quantum resources, such as the number of circuit evaluations and the number of operators used to construct circuits, which is crucial for practical implementations on actual near-term processors.
For molecules such as BeH2 at large Be-H bond lengths, a complex initial state is required for the algorithm to be able to reach the ground state using the available operators. Even in these cases, by leveraging an efficient state preparation scheme implemented in InQuanto, the Hive evolved a dedicated strategy for the preparation of such a complex initial state, given a set of basic operators to achieve the desired chemical precision.
To validate Hive-ADAPT under realistic conditions, we employed ║┌┴Ž╔ńŌĆÖs H2 Emulator, which provides a faithful classical simulator of the H2 quantum computer, characterised by a 1.05e-3 two-qubit gate error rate. Leveraging the Hive's inherent flexibility, we adapted the optimisation strategy to explicitly penalise the number of two-qubit gatesŌĆöthe dominant noise source on near-term hardwareŌĆöby redefining the fitness function. This constraint guided the Hive to discover a noise-aware algorithm capable of constructing hardware-efficient circuits. We subsequently executed the specific circuit generated by this algorithm for the LiH molecule at a bond length of 1.5 ├ģ with the Partition Measurement Symmetry Verification (PMSV) error mitigation procedure. The resulting energy of -7.8767 ┬▒ 0.0031 Ha, obtained using 10,000 shots per circuit with a discard rate below 10% in the PMSV error mitigation procedure, is close to the target FCI energy of -7.8824 Ha and demonstrates the Hive's ability to successfully tailor algorithms that balance theoretical accuracy with the rigorous constraints of hardware noise and approach chemical precision as much as possible with current quantum technology.
For illustration purposes, we show an example of an elaborate code snippet evolved by the Hive starting from a trivial version:
║┌┴Ž╔ńŌĆÖs in-house quantum chemistry expert, Dr. David Zsolt Manrique, commented,
ŌĆ£I found it amazing that the Hive converged to a domain-expert level idea. By inspecting the code, we see it has identified the well-known perturbative method, ŌĆśMP2ŌĆÖ, as a useful guide; not only for setting the initial circuit parameters, but also for ordering excitations efficiently. Further, it systematically and laboriously fine-tuned those MP2-inspired heuristics over many iterations in a way that would be difficult for a human expert to do by hand. It demonstrated an impressive combination of domain expertise and automated machinery that would be useful in exploring novel quantum chemistry methods.ŌĆØ
Looking to the Future
In this initial proof-of-concept collaborative study between ║┌┴Ž╔ń and Hiverge, we demonstrate that AI-driven algorithm discovery can generate efficient quantum heuristics. Specifically, we found a great reduction in quantum resources, which is impactful for quantum algorithmic primitives that are frequently reused. Importantly, this approach is highly flexible; it can accommodate the optimisation of any desired quantum resource, from circuit evaluations to the number of operations in a given circuit. This work opens a path toward fully automated pipelines capable of developing problem-specific quantum algorithms optimised for NISQ as well as future hardware.
An important question for further investigation regards transferability and generalisation of a discovered quantum solution to other molecules, going beyond the generalisation over bond lengths of the same molecule that we have already observed. Evidently, this approach can be applied to improving any other near-term quantum algorithm for a range of applications from optimisation to quantum simulation.
We have already demonstrated an error-corrected implementation of quantum phase estimation on quantum hardware, and an AI-driven approach promises further hardware-tailored improvements and optimal use of quantum resources. Beyond NISQ, we envision that AI-assisted algorithm discovery will be a fruitful endeavour in the fault-tolerant regime, as well, where high-level quantum algorithmic primitives (quantum fourier transform, amplitude amplification, quantum signal processing, etc.) are to be combined optimally to achieve computational advantage for certain problems.
Notably, weŌĆÖve entered an era where quantum algorithms can be written in high-level programming languages, like ║┌┴Ž╔ńŌĆÖs , and approaches that integrate Large Language Models directly benefit. Automated algorithm discovery is promising for improving routines relevant to the full quantum stack, for example, in low-level quantum control or in quantum error correction.
║┌┴Ž╔ń is focusing on redefining whatŌĆÖs possible in hybrid quantumŌĆōclassical computing by integrating ║┌┴Ž╔ńŌĆÖs best-in-class systems with high-performance NVIDIA accelerated computing to create powerful new architectures that can solve the worldŌĆÖs most pressing challenges.┬Ā
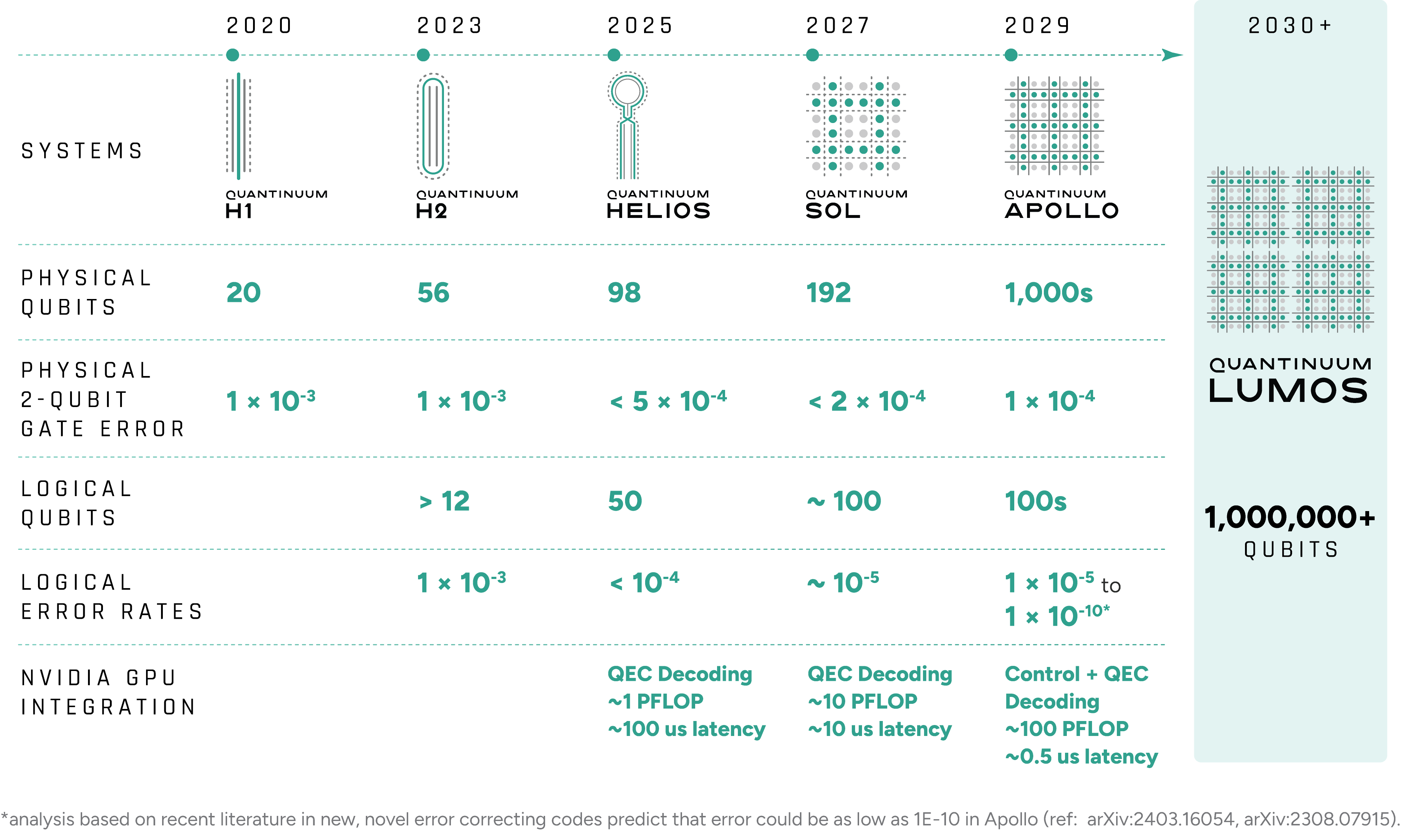
The launch of Helios, Powered by Honeywell, the worldŌĆÖs most accurate quantum computer, marks a major milestone in quantum computing. Helios is now available to all customers through the cloud or on-premise deployment, launched with a go-to-market offering that seamlessly pairs Helios with the , targeting specific end markets such as drug discovery, finance, materials science, and advanced AI research.┬Ā
We are also working with NVIDIA to adopt┬Ā , an open system architecture, as a standard for advancing hybrid quantum-classical supercomputing. Using this technology with ║┌┴Ž╔ń Guppy and the , ║┌┴Ž╔ń has implemented NVIDIA accelerated computing across Helios and future systems to perform real-time decoding for quantum error correction.┬Ā
In an industry-first demonstration, an NVIDIA GPU-based decoder integrated in the Helios control engine improved the logical fidelity of quantum operations by more than 3% ŌĆö a notable gain given HeliosŌĆÖ already exceptionally low error rate. These results demonstrate how integration with NVIDIA accelerated computing through NVQLink can directly enhance the accuracy and scalability of quantum computation.
This unique collaboration spans the full ║┌┴Ž╔ń technology stack. ║┌┴Ž╔ńŌĆÖs next-generation software development environment allows users to interleave quantum and GPU-accelerated classical computations in a single workflow. Developers can build hybrid applications using tools such as NVIDIA CUDA-Q, , and ║┌┴Ž╔ńŌĆÖs Guppy, to make advanced quantum programming accessible to a broad community of innovators.
The collaboration also reaches into applied research through the (NVAQC), where an NVIDIA GB200 NVL72 supercomputer can be paired with ║┌┴Ž╔ńŌĆÖs Helios to further drive hybrid quantum-GPU research, including┬Ā the development of breakthrough quantum-enhanced AI applications.
A recent achievement illustrates this potential: The ADAPT-GQE framework, a transformer-based Generative Quantum AI (GenQAI) approach, uses a Generative AI model to efficiently synthesize circuits to prepare the ground state of a chemical system on a quantum computer. Developed by ║┌┴Ž╔ń, NVIDIA, and a pharmaceutical industry leaderŌĆöand leveraging NVIDIA CUDA-Q with GPU-accelerated methodsŌĆöADAPT-GQE achieved a 234x speed-up in generating training data for complex molecules. The team used the framework to explore imipramine, a molecule crucial to pharmaceutical development. The transformer was trained on imipramine conformers to synthesize ground state circuits at orders of magnitude faster than ADAPT-VQE, and the circuit produced by the transformer was run on Helios to prepare the ground state using InQuanto, ║┌┴Ž╔ń's computational chemistry platform.
From collaborating on hardware and software integrations to GenQAI applications, the collaboration between ║┌┴Ž╔ń and NVIDIA is building the bridge between classical and quantum computing and creating a future where AI becomes more expansive through quantum computing, and quantum computing becomes more powerful through AI.
By Dr. Noah Berthusen
The earliest works on quantum error correction showed that by combining many noisy physical qubits into a complex entangled state called a "logical qubit," this state could survive for arbitrarily long times. QEC researchers devote much effort to hunt for codes that function well as "quantum memories," as they are called. Many promising code families have been found, but this is only half of the story.
Being able to keep a qubit around for a long time is one thing, but to realize the theoretical advantages of quantum computing we need to run quantum circuits. And to make sure noise doesn't ruin our computation, these circuits need to be run on the logical qubits of our code. This is often much more challenging than performing gates on the physical qubits of our device, as these "logical gates" often require many physical operations in their implementation. What's more, it often is not immediately obvious which logical gates a code has, and so converting a physical circuit into a logical circuit can be rather difficult.
Some codes, like the famous , are good quantum memories and also have easy logical gates. The drawback is that the ratio of physical qubits to logical qubits (the "encoding rate") is low, and so many physical qubits are required to implement large logical algorithms. High-rate codes that are good quantum memories have also been found, but computing on them is much more difficult. The holy grail of QEC, so to speak, would be a high-rate code that is a good quantum memory and also has easy logical gates. Here, we make progress on that front by developing a new code with those properties.
Building on prior error correcting codes
A recent work from ║┌┴Ž╔ń QEC researchers introduced . The underlying construction method for these codes, called the "symplectic double cover," also provided a way to obtain logical gates that are well suited for ║┌┴Ž╔ń's QCCD architecture. Namely, these "SWAP-transversal" gates are performed by applying single qubit operations and relabeling the physical qubits of the device. Thanks to the all-to-all connectivity facilitated through qubit movement on the QCCD architecture, this relabeling can be done in software essentially for free. Combined with extremely high fidelity (~1.2 x10-5) single-qubit operations, the resulting logical gates are similarly high fidelity.
Given the promise of these codes, we take them a step further in our . We combine the symplectic double codes with the [[4,2,2]] Iceberg code using a procedure called "code concatenation". A concatenated code is a bit like nesting dolls, with an outer code containing codes within it---with these too potentially containing codes. More technically, in a concatenated code the logical qubits of one code act as the physical qubits of another code.
The new codes, which we call "concatenated symplectic double codes", were designed in such a way that they have many of these easily-implementable SWAP-transversal gates. Central to its construction, we show how the concatenation method allows us to "upgrade" logical gates in terms of their ease of implementation; this procedure may provide insights for constructing other codes with convenient logical gates. Notably, the SWAP-transversal gate set on this code is so powerful that only two additional operations (logical T and S) are necessary for universal computation. Furthermore, these codes have many logical qubits, and we also present numerical evidence to suggest that they are good quantum memories.
Concatenated symplectic double codes have one of the easiest logical computation schemes, and we didnŌĆÖt have to sacrifice rate to achieve it. Looking forward in our roadmap, we are targeting hundreds of logical qubits at ~ 1x 10-8 logical error rate by 2029. These codes put us in a prime position to leverage the best characteristics of our hardware and create a device that can achieve real commercial advantage.